数据结构
|
|
hash函数
|
|
解决hash冲突
- 拉链法解决冲突
解决拉链法解决冲突的弊端
redis使用的是渐进式重散列(incremental rehashing)
- 重散列
创建一个更大的hash表,把原来旧的数据一次性全部重新hash到新的表上。 - 渐进式重散列
创建一个更大的hash表,把原来旧的数据分步(如get或者set操作时,每次都只重新hash1个)重新hash到新的表上。
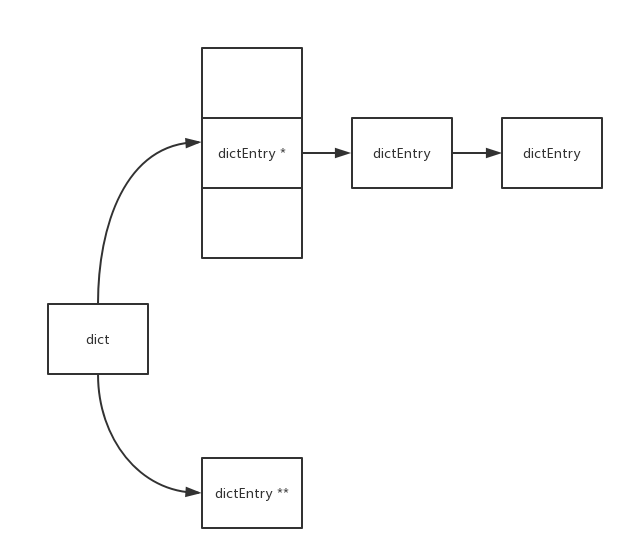
如上图dict中有两个hash tabe, 其中ht[1]就是在重散列时用到的。
渐进式重散列的时机
- get
- set
- delete
- …
反向递增二进制扫描器(dictScan)
正常的游标递增是从1,2,3,4,5 … 自然数加1递增的, 用二进制描述是从最低位加1, 若溢出则向高位进位。
1000 001 010 011 100 101 110 111而dictScan的游标递增方式比较特别, 用二进制描述是从最高位加1, 若溢出则向低位进位。
1000 100 010 110 001 101 011 111dictScan采用这样特殊的游标递增方式是为了避免在扩容重散列时导致数据读取重复问题和缩容重散列时导致数据读取遗漏。
- dictScan也不是完美的,其在扩容重散列时没有问题,但在缩容重散列时有可能会导致读取到少量重复数据。
扩容和缩容前后游标对应关系图
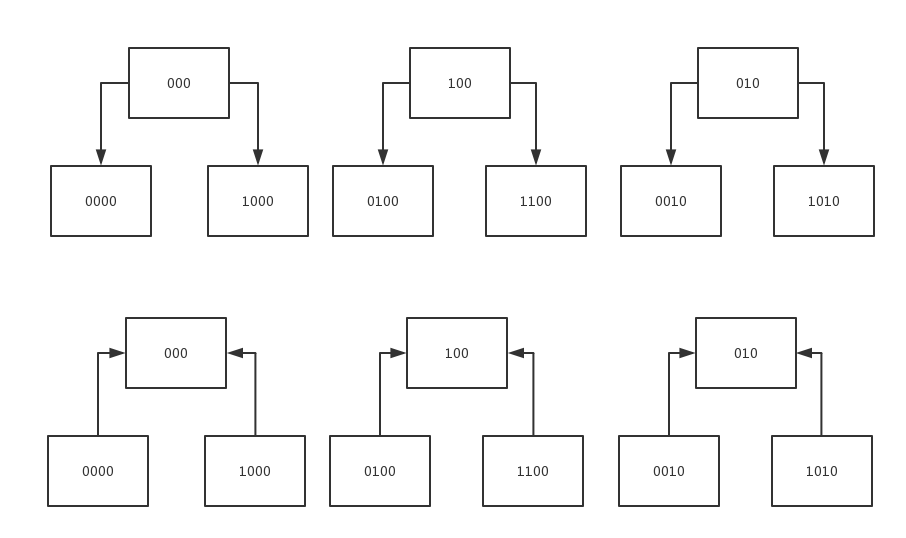
- 上图是扩容,通俗点理解原来一个变成了两个,由于原来的到新的没有重合的,所以没有重复读取的情况
- 下图是缩容,通俗点理解原来两个变成了一个,由于原来到新的是合二为一有重合,所以有可能会出现重复读取的情况,但这也是为了不遗漏数据所必要的,
没有重复的情况是当下一个应读取下一组时就不会读取到重复数据。 另外,重复bucket的数量=(bigger_table_size / smaller_table_size) - 1

