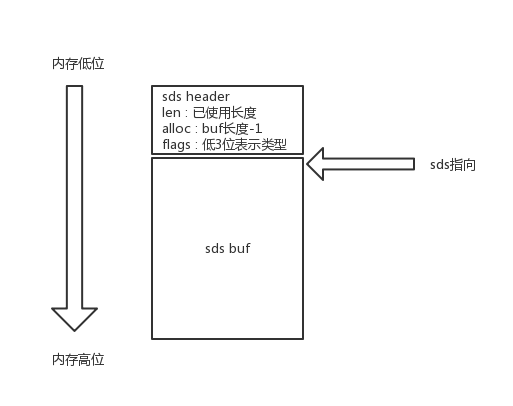
简介
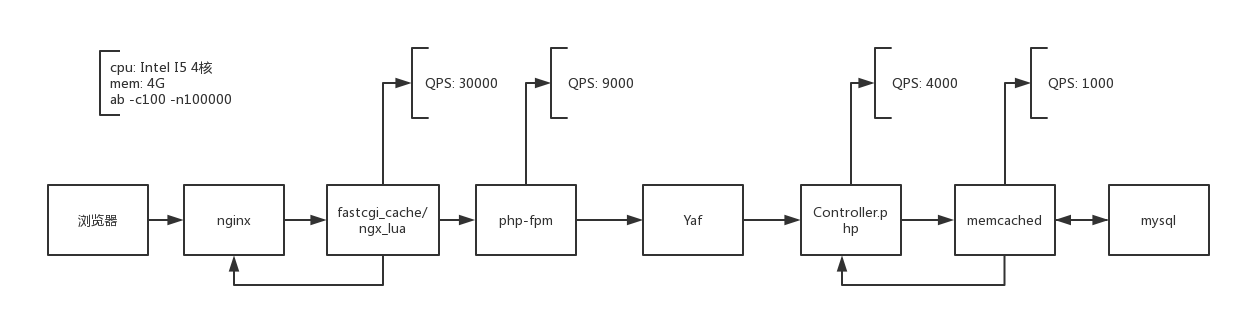
使用ngx_lua模块在Nginx层做缓存,可动态控制缓存开关,可做静态方案或者降级方案,
在公司的一个专题页项目中使用该方案,QPS提高了20倍
架构图
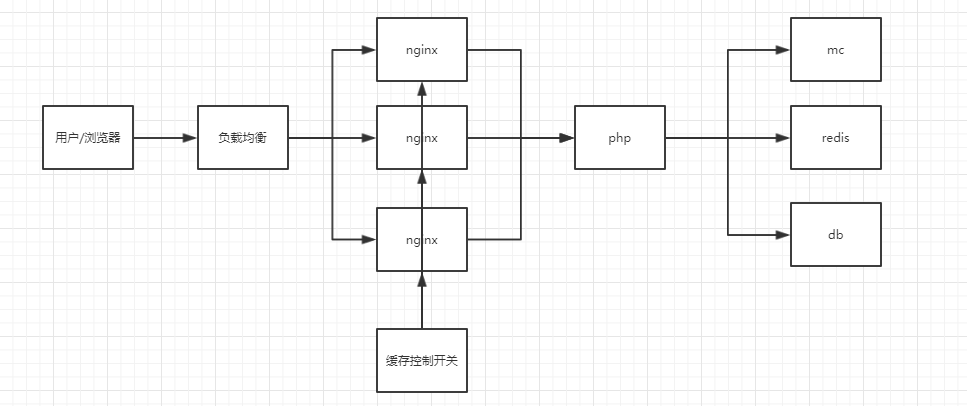
Lua代码文件
header_filter.lua文件
|
|
access.lua文件
|
|
Nginx主要配置
|
|
缓存开关控制脚本
|
|
使用ngx_lua模块在Nginx层做缓存,可动态控制缓存开关,可做静态方案或者降级方案,
在公司的一个专题页项目中使用该方案,QPS提高了20倍
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
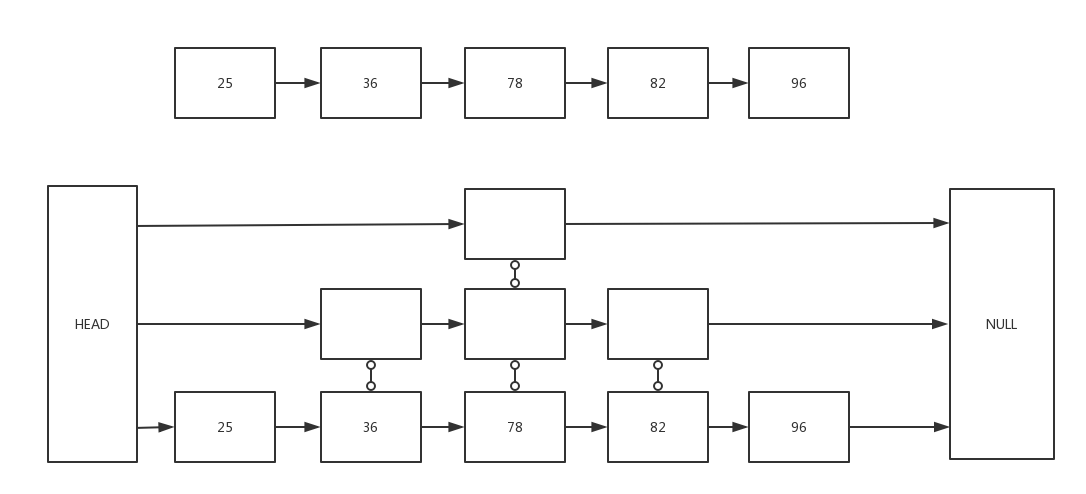
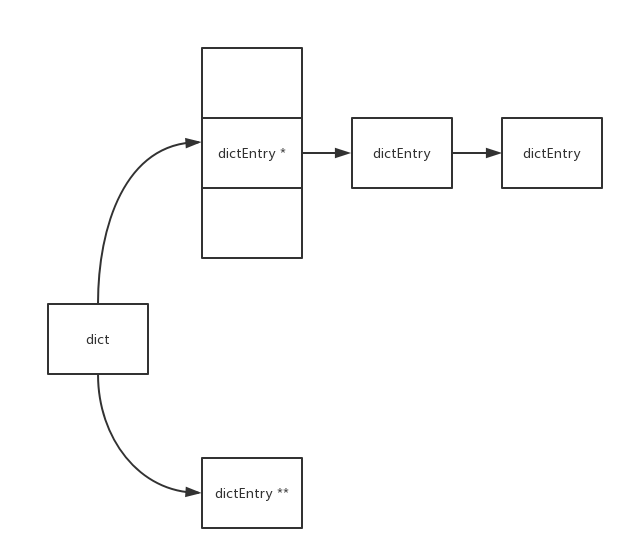
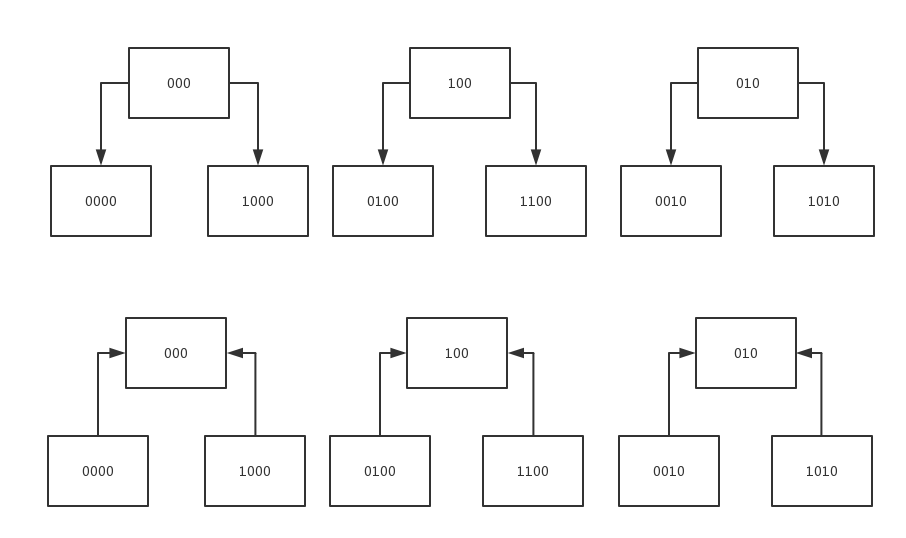
redis使用的是渐进式重散列(incremental rehashing)
正常的游标递增是从1,2,3,4,5 … 自然数加1递增的, 用二进制描述是从最低位加1, 若溢出则向高位进位。
|
|
而dictScan的游标递增方式比较特别, 用二进制描述是从最高位加1, 若溢出则向低位进位。
|
|
dictScan采用这样特殊的游标递增方式是为了避免在扩容重散列时导致数据读取重复问题和缩容重散列时导致数据读取遗漏。
|
|
- 常用缓存(memcached和redis)
- Nginx的缓存(标准模块缓存: proxy_cache和fastcgi_cache / 第三方模块做缓存: ngx_lua)
- CDN缓存
- 浏览器缓存(Cache-Control和LocalStorage)
proxy_cache和fastcgi_cache都为Nginx的内置缓存,proxy_cache主要用于反向代理时,对后端内容源服务器进行缓存,fastcgi_cache主要用于对FastCGI的动态程序进行缓存。
两者相关配置类似,以下为fastcgi_cache举例
针对fastcgi(如:php-fpm)返回的内容缓存为静态文件(文件名是用Md5算法对Key进行哈希后所得,而Key可使用fastcgi_cache的相关指令来进行控制)
,在用户浏览时,无需重复请求后端fastcgi,而直接返回缓存的内容,减少了后端的语言解析以及数据库连接的消耗。
fastcgi_cache_path /home/wwwroot/yii.me/runtime/logs levels=1:2 keys_zone=keys_zone=zone:512m:1m inactive=1d
max_size=1g; #指定一个路径,目录结构等级,关键字区域存储时间和非活动删除时间。以及最大占用空间(keys_zone主要缓存key和文件元信息,不会缓存页面)
fastcgi_cache zone; #表示开启FastCGI缓存并为其指定一个名称:zone
fastcgi_cache_valid 1m; #设置缓存时间1分钟
fastcgi_cache_min_uses 1; #设置链接请求1次就被缓存
fastcgi_cache_use_stale error timeout invalid_header http_500; #定义哪些情况下用过期缓存(如果对实效要求不高建议加updating,关闭fastcgi_cache_lock,可提高性能)
fastcgi_cache_methods GET POST; #缓存GET和POST请求
fastcgi_cache_key “$cache_path$containerid$containerpage”; #缓存key=页面+containerid+分页页码
fastcgi_ignore_headers Cache-Control Expires Set-Cookie; #包含这些header的响应不缓存
fastcgi_cache_lock on; #同时有请求处理的时候只有一个请求允许访问后端服务器,其余请求等待缓存结果或等待超时再进行响应
fastcgi_cache_lock_timeout 5s; #等待超时时间5秒,超时则穿透,且不缓存穿透结果
fastcgi_cache_bypass $skip_cache; #非0不从cache中取
fastcgi_no_cache $skip_cache; #非0不保存到cache
以下测试使用的vps机器
ab -c10 -n50000 http://127.0.0.1:8080/echo.php
|
|
永恒之蓝勒索病毒文件加密解密流程,核心使用RSA+AES
以上可知,只要作者的RSA私钥A.private不泄露,那些被加密的文件理论无法破解
而作者提出使用比特币作为支付方式,是利用比特币的匿名性和无法被冻结,但比特币的交易记录是公开的,作者没有办法把每笔交易和某个感染用户关联,所以即使支付赎金,也可能无法解密文件
这两个命令是用来查看和改变文件、目录属性的,与chmod这个命令相比,chmod只是改变文件的读写、执行权限,更底层的属性控制是由chattr来改变的
|
|
|
|
|
|
|
|
监听
|
|
连接
|
|
|
|
|
|
|
|
|
|
|
|
每周4下午3点显示一个提醒弹窗
|
|
mac版弹窗命令
|
|
设置命令别名,可缩短命令长度
例如1234sudo vim /home/当前用户/.bashrc ;对当前用户有效sudo vim /etc/profile ;全局用户有效source /etc/profilealias sqlmap=’python /path/sqlmap.py’
|
|